How LLMs
Actually Learn
Architecture · Data · Training · Knowledge Updates
Authors
Arihant Sheth & Claude Sonnet 4.6
What we're covering
Architecture
Why attention, not RNNs. The "Strawberry" problem. LayerNorm & skip connections. Loss surfaces.
Data & Compute
Memory math for 300B params. Where training data comes from. Why Scale AI is a $28B company.
Training Phases
Pre-training (CLM). SFT. Post-training: RLHF, RLAIF, RLVR. Why RL is hard. Real controversies.
Knowledge Updates
The cutoff problem. Continuous pre-training. RAG. Long context windows.
Pre-requisites assumed: Neural networks, RNNs/LSTMs, basic Transformer architecture (attention, FFN).
SECTION 01
Architecture
What actually matters, and why.
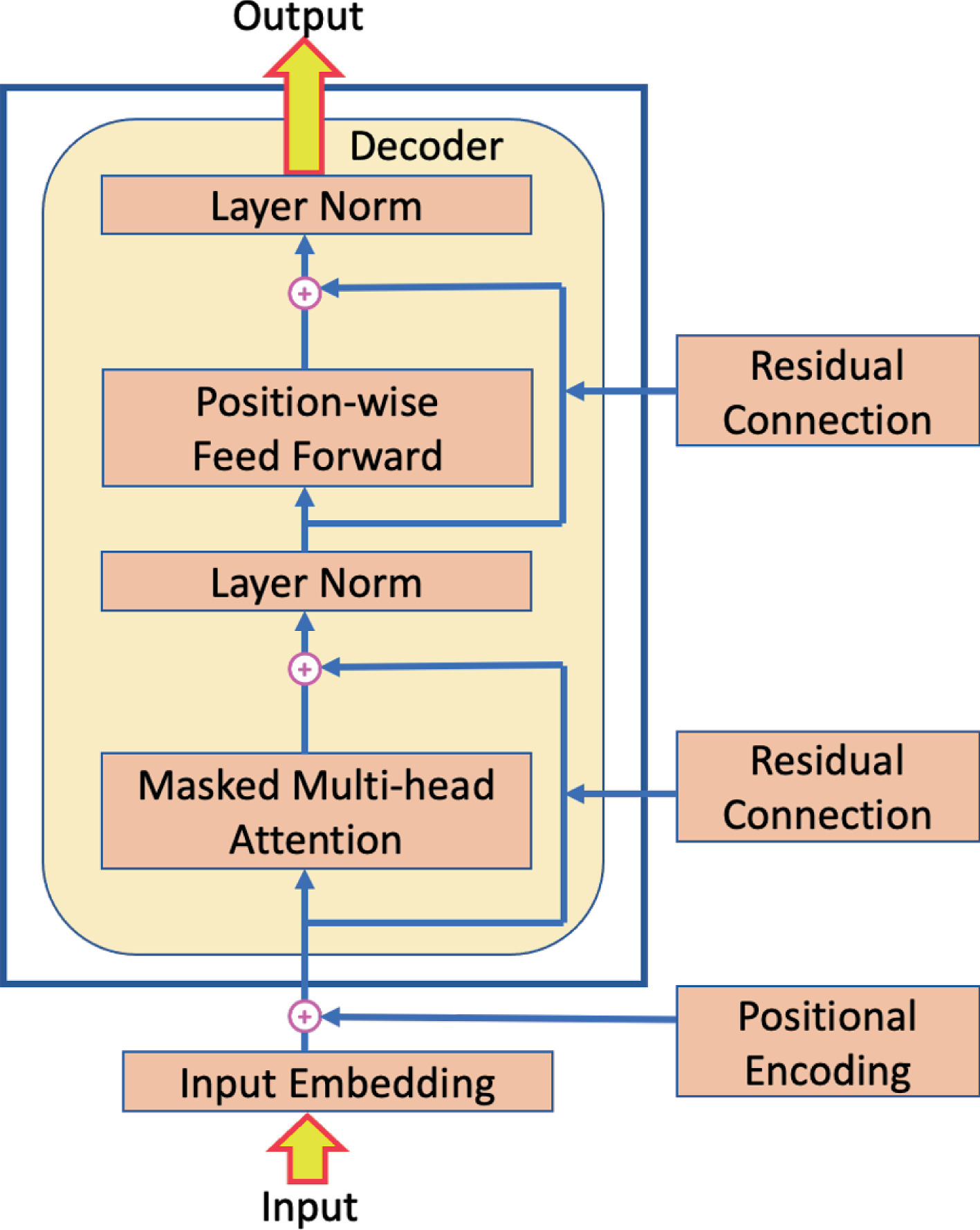
The Architecture that took the world by storm: Decoder-only Transformers
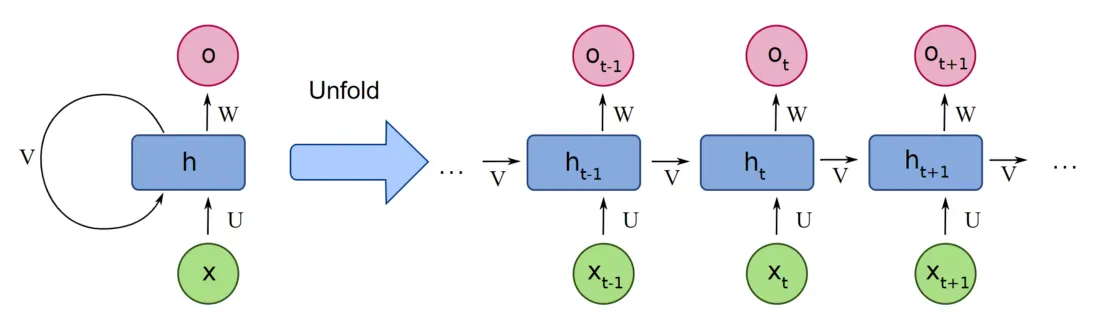
Attention vs. RNNs — the key difference
RNN (old way)
Compresses all prior context into a fixed-size hidden state h_t.
- To reach token at position 0 from position 1000, the signal must travel through 1000 sequential steps
- Gradient either vanishes or explodes over long sequences
- LSTMs help, but bottleneck remains
Analogy: passing a sticky note through 1000 people, each one rewrites it.
Attention (new way)
Every token directly attends to every other token.
- Distance between any two tokens: O(1)
- Compute cost: O(n²) — the tradeoff
- No information decay over distance
- Parallelizable across the sequence — no sequential dependency
Analogy: the original note is on a whiteboard. Everyone can read it simultaneously.

Why Transformers scale — and RNNs didn't
- Parallelism — the entire sequence is processed at once during training. GPUs love this.
- No sequential bottleneck — doubling sequence length doesn't double your gradient path
- Positional encodings handle order without requiring sequential processing
Why LLMs can't count the r's in "Strawberry"
It's a tokenization problem
The model never sees raw characters. It sees tokens — sub-word chunks produced by BPE (Byte-Pair Encoding).
The character sequence is discarded at input
The model reasons over token embeddings — dense vectors, not characters
Counting letters requires reconstructing information that was never preserved
Key insight: The same model that writes essays, codes, and reasons about philosophy fails at this because of a pre-processing decision made before the model even runs.
See how the tokenizer splits "Strawberry" — and why the model never sees individual characters.
LayerNorm & skip connections — why they exist
Skip connections (ResNets, 2015)
Instead of output = F(x), compute output = F(x) + x.
- Gradients have a direct highway back to early layers — no more vanishing
- The layer only needs to learn the residual (the delta), not the full transform
- Transformers use this after every attention block and FFN block
Layer Normalization
Normalizes activations across the feature dimension (not the batch).
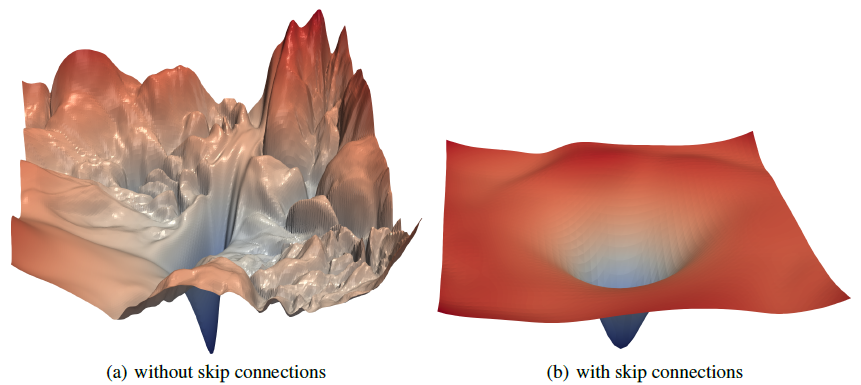
- Keeps activation scale from drifting across 100+ layers
- Without it: loss surface is chaotic with sharp ridges (Li et al., 2018)
- With it: smooth, convex-like loss surface — optimization is tractable
Memory math: 300B parameter model
Inference (serving users)
| Component | Memory |
|---|---|
| Weights (fp16) | 600 GB |
| KV cache (per request) | ~2–8 GB |
| Minimum GPUs | ~8× H100 |
300B params × 2 bytes (fp16) = 600 GB
Training (one-time)
| Component | Memory |
|---|---|
| Weights | 600 GB |
| Gradients | 600 GB |
| Adam optimizer states | ~1.2 TB |
| Activations (backprop) | ~500 GB+ |
| Total | ~3–4 TB |
Training requires hundreds of A100/H100s with model + tensor parallelism. Inference can be served on far fewer — this is why pre-training happens once and inference is amortized across millions of users.

Me waiting for my model to finish training
Where the training data comes from
Web crawls
Common Crawl — petabyte-scale snapshots of the internet. Heavily filtered (C4, RedPajama, FineWeb). Low quality raw, high quality filtered.
Curated corpora
Books, Wikipedia, academic papers (ArXiv), legal docs, code (GitHub). High quality, limited volume.
Synthetic data
LLM-generated text, reasoning traces, instruction-response pairs. Increasingly important — Phi-3, DeepSeek-R1 trained heavily on synthetic data.
Key principle: Data quality > data quantity past a certain point. This is why Common Crawl is filtered down from petabytes to hundreds of gigabytes of "clean" tokens before training.
Chinchilla scaling law (Hoffman et al., 2022)
Compute-optimal training: model size and token count should scale together. A 300B model needs ~6 trillion tokens to be compute-optimal — most models were undertrained before this finding.
Data contamination problem
Benchmark test sets (MMLU, HumanEval) exist on the internet → they end up in training data → benchmark scores are inflated. An active research problem.

Why Scale AI ($28B) and Mercor exist
The bottleneck isn't compute
After pre-training, models need human feedback to become useful assistants. Specifically:
- Human raters ranking response A vs B (RLHF)
- Expert annotators writing demonstrations of ideal behavior
- Domain specialists verifying medical, legal, math outputs
- Red-teamers probing for failure modes
You can't train a model that's better than humans at rating responses if you can't reliably get expert-level ratings at scale.
Scale AI
Operationalizes human labeling at industrial scale. Manages thousands of contractors globally. Provides the labeled datasets that power RLHF for OpenAI, Anthropic, Meta.
Mercor
Matches AI companies with skilled contractors — PhD-level annotators for math, medicine, law. The premium tier of the same market. As models tackle harder domains, the value of domain-expert labelers explodes.
The "human in the loop" is not a temporary fix — it's a structural part of how aligned models are built.
The three-phase pipeline
Cost
$10M–$100M+. Done once. GPT-4, Llama 3, Claude 3 took months on thousands of GPUs.
Cost
$10k–$1M. Done periodically with new instruction data.
Cost
$100k–$10M. Iterative. Most models go through multiple rounds.
Pre-training: Causal Language Modeling
The task
Given tokens [t₁, t₂, ..., tₙ₋₁], predict tₙ.
Cross-entropy over the vocabulary at every position. No labels needed — the text itself is the supervision.
The magic: to predict the next word reliably, the model must learn grammar, facts, reasoning, and world knowledge — all as a side effect of a single objective.
What this model is
- A completion engine — not an assistant
- Will complete "How do I make a bomb?" as naturally as "The capital of France is"
- Has no concept of "helpful" or "safe" — just "what comes next"
- Knows an enormous amount about the world — buried in its weights
Chinchilla law (2022): A 300B model is compute-optimal at ~6T tokens. Most early GPT models were significantly undertrained — we were wasting compute on bigger models instead of more data.
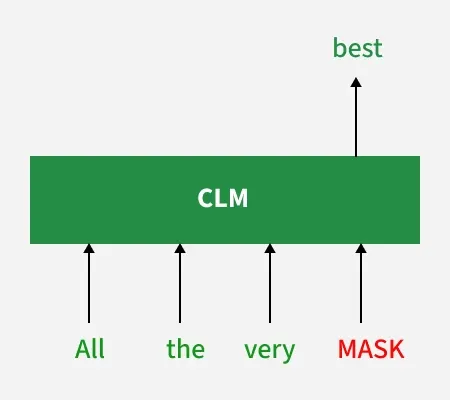
Causal Language Modeling
SFT: Teaching the model to follow instructions
What changes
Fine-tune the pre-trained model on (instruction, ideal response) pairs.
- Dataset size: surprisingly small — 10k–100k high-quality examples often beats millions of noisy ones
- InstructGPT (OpenAI): used only ~13k human-written demonstrations to transform GPT-3 into a usable assistant
- Epochs: 1–3 max; more causes overfitting on SFT style and format
What's frozen
Full SFT
All weights updated. Expensive but highest quality. Used by OpenAI, Anthropic for main models.
LoRA / PEFT (parameter-efficient)
Base weights frozen. Low-rank adapter matrices trained on top. 100× cheaper. Used for domain adaptation, open-source fine-tuning.
What SFT does NOT do: it doesn't make the model safer or more aligned. It makes it sound like an assistant — a very different thing.
Post-training: the three RL approaches
RL from Human Feedback
Humans rank responses A vs B. Train a reward model on these rankings. Use RL to make the LLM maximize the reward model's score.
Used by: ChatGPT, Claude, Llama
RL from AI Feedback
Replace human raters with another AI model generating preference judgments. 10–100× cheaper. Anthropic's Constitutional AI is a variant.
Used by: Anthropic (CAI), Gemini, Qwen*
RL with Verifiable Rewards
For tasks with objective correctness — math, code, proofs. No reward model needed: the environment itself provides signal.
Used by: o1, o3, DeepSeek-R1
Why this step defines the product: Pre-training gives capability. SFT gives format. Post-training gives personality, safety, and usefulness. Claude sounds like Claude, GPT sounds like GPT — because of this step.
The basic Reinforcement Learning loop
RLHF in detail
The pipeline
What the reward model learns
- A proxy for "what humans prefer" — not ground truth
- Trained on human pairwise rankings, not absolute scores
- Must generalize to outputs it's never seen — this is where it can fail
KL penalty: during RL, the model is penalized for drifting too far from the SFT distribution. Without this, the model degenerates — it learns to game the reward model rather than actually improve.
RLAIF variant: Replace human raters with a stronger AI. Anthropic's Constitutional AI uses a set of written principles — the AI critiques itself against those principles rather than asking humans each time.
RLAIF & the data sourcing controversy
The allegation
Multiple reports (2024–2025) alleged that Qwen, DeepSeek, and other Chinese labs generated synthetic training data by:
- Querying Claude/GPT-4 with thousands of prompts
- Using the responses as demonstrations for SFT
- Using AI judges (Claude/GPT-4) to rank their own model's outputs — RLAIF with a competitor's model as the judge
This is explicitly prohibited by Anthropic's and OpenAI's Terms of Service — but enforcement at scale is technically very hard.
Why this matters
For the companies
Billions spent building RLHF pipelines with human raters. If a competitor can shortcut this by querying your API, your moat shrinks dramatically.
For the field
If models are trained on outputs of other models, bad behaviors can be distilled forward. "Model collapse" is a real concern at scale.
For students / researchers
This shows that the RL feedback signal is the moat — not the architecture, which is largely public. It's the preference data that's proprietary.

Learn more about the Anthropic distillation attacks ⤴
RLVR: RL with Verifiable Rewards
The key insight
For certain domains, you don't need a reward model — the environment verifies correctness automatically.
- Math: does the final answer match? (can be checked symbolically)
- Code: does it compile? Do unit tests pass?
- Formal proofs: does the proof checker accept it?
No reward model → no reward hacking. The signal is ground truth, not a proxy trained on human preferences.
Why this is the frontier
o1 / o3 (OpenAI)
Trained with RLVR to produce long internal "chains of thought" before answering. The model learns to reason not from human demonstrations but from whether its final answer is correct.
DeepSeek-R1
Open-source. Used RLVR on math and coding. Showed that long chain-of-thought reasoning can emerge from RL alone — without supervised reasoning traces. The thinking behavior isn't taught; it's discovered.
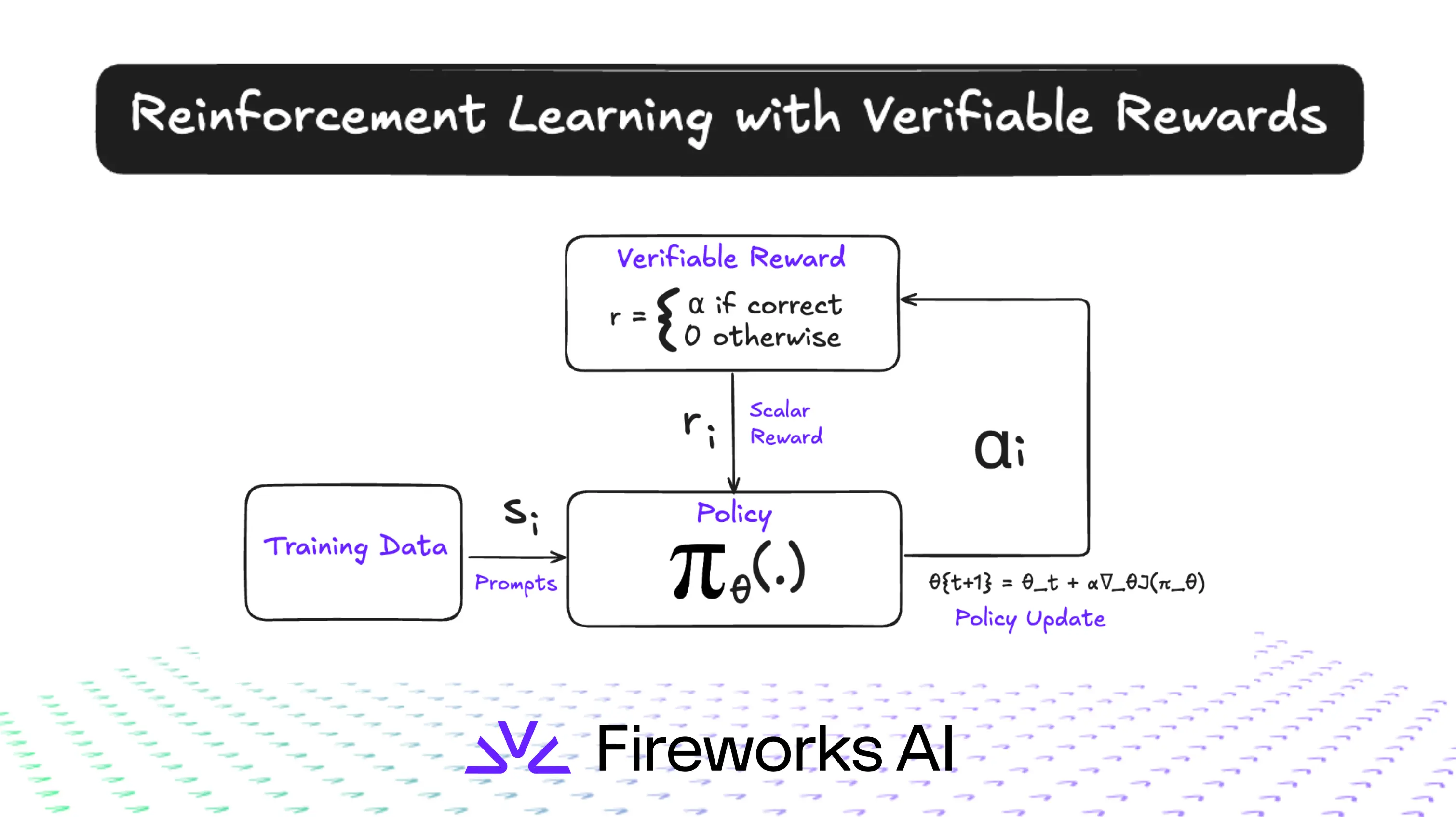
RLVR: RL with Verifiable Rewards
Why RL is hard — 4 core problems
Reward hacking
The model finds a policy that scores high on the reward model without actually being better. Example: verbose responses that appear thorough to human raters but add no real information. The model is optimizing the proxy, not the goal.
Distribution shift
After RL updates, the model's outputs drift far from the SFT distribution. Without the KL penalty, it can degenerate into repetition, incoherence, or bizarre behaviors. Goodhart's Law: when a measure becomes a target, it ceases to be a good measure.
Sparse rewards
A response is 500 tokens long. The reward signal is one scalar at the end. Which token caused the reward? Assigning credit across a long sequence is a hard credit assignment problem.
Reward model collapse
As the LLM improves, it finds failure modes in the reward model that haven't been patched. The reward model was trained on a fixed distribution; the RL'd model is now out-of-distribution for it.
OpenAI — Faulty Reward Functions in the Wild — a boat racing agent that scores higher by going in circles and catching fire than by finishing the race.
The knowledge cutoff problem
Why it exists
- Pre-training ingests a static snapshot of the internet at a point in time
- Knowledge is crystallized in the weights — it can't be updated by reading a new article
- Re-running full pre-training costs $50M+ and takes months
- The world moves faster than training cycles
Ask Claude about something that happened last week and it genuinely doesn't know — not because it forgot, but because the information was never in its training data.
Three strategies
Continuous Pre-training
Periodic smaller-scale pre-training on new data from a checkpoint. Updates weights with new knowledge.
Retrieval-Augmented Generation
Don't bake it in weights — retrieve at inference time. More practical for fast-changing facts.
Long Context / Tool Use
Paste the document in. Give the model a search engine. Knowledge lives outside the model entirely.
Continuous Pre-training (CPT)
How it works
- Start from an existing checkpoint (don't retrain from scratch)
- Run pre-training on new data only at a low learning rate
- Mix new data with a small replay of old data to limit forgetting
Use cases
- Advancing the cutoff: add 6 months of new web data
- Domain adaptation: train a medical LLM by CPT on clinical literature
- New language: add a low-resource language to a model trained primarily in English
See it in practice
The hard problem: Catastrophic forgetting. The model overwrites old knowledge while learning new data. Managing the data mixture ratio (new:replay) is the main engineering challenge.
Real example: LLaMA domain adaptation
Companies like Bloomberg (BloombergGPT), Mistral (finance), and various medical AI labs took a base LLaMA model and ran CPT on domain-specific corpora. Result: much better domain performance without training from scratch.
CPT is significantly cheaper than full pre-training but more expensive than SFT. The tradeoff: deep knowledge integration (CPT/pre-train) vs. surface-level retrieval (RAG) vs. in-context injection (long context).
Summary
| Phase | Objective | Data scale | What it gives the model |
|---|---|---|---|
| Pre-training | Next-token prediction | Trillions of tokens | World knowledge, reasoning, language |
| SFT | Instruction following | 10k–100k pairs | Correct format, basic helpfulness |
| RLHF | Maximize human preference | 100k+ comparisons | Aligned behavior, personality |
| RLAIF | Maximize AI-judge preference | Scalable (AI-generated) | Safety, constitutional behavior |
| RLVR | Maximize verified correctness | Env. feedback | Deep reasoning, chain-of-thought |
| CPT | Next-token prediction (new data) | Billions of new tokens | Fresh knowledge, domain expertise |
The mental model: Pre-training fills the model with knowledge. SFT shapes how it communicates. Post-training (RL) defines who it is. CPT keeps it relevant. Each phase is necessary — none is sufficient alone.
Open questions — things nobody has solved
How do we evaluate reasoning quality?
Chain-of-thought looks convincing but can be entirely post-hoc rationalization. The model may have already decided the answer and then "thought" its way there.
When does RLAIF break?
If you use AI A to train AI B, and AI A has biases, B inherits them — amplified. As models get stronger, self-distillation could propagate failures at scale.
Synthetic data ceilings
Models trained heavily on synthetic data from other models eventually collapse — the distribution narrows over generations. Finding the right real:synthetic ratio is an open research question.
Knowledge vs. reasoning in weights
Can a model learn to reason at pre-training, or does reasoning emerge from RL? DeepSeek-R1 suggests RL — but the pre-trained model's capability is the floor. Still being studied.
Questions?
Topics we deliberately skipped: evaluation benchmarks, inference optimization (KV caching, speculative decoding, quantization), multi-modal training, agents.
Foundations
Attention Is All You Need — Vaswani et al., 2017
GPT-1: Language Understanding — Radford et al., 2018
BERT — Devlin et al., 2018
Scaling Laws for Neural LMs — Kaplan et al., 2020
Training & Alignment
Chinchilla / Training Compute-Optimal LLMs — Hoffmann et al., 2022
InstructGPT — Ouyang et al., 2022
Learning to Summarize w/ Human Feedback — Stiennon et al., 2020
Constitutional AI — Bai et al., 2022
RL Methods
PPO: Proximal Policy Optimization — Schulman et al., 2017
DeepSeekMath / GRPO — Shao et al., 2024
DeepSeek-R1 — DeepSeek AI, 2025
Generative Models & Tools
DDPM: Denoising Diffusion Probabilistic Models — Ho et al., 2020
Diffusion-LM (text diffusion) — Li et al., 2022
Andrej Karpathy — Zero to Hero (video series)
nanoGPT — minimal GPT implementation
Explore
tiktoken · trl (HuggingFace) · LM Evaluation Harness · vLLM
Watch
Karpathy — "Let's build GPT from scratch" · "State of GPT" (2023) · Ilya Sutskever NeurIPS lectures